Hollywood executives are tasked with coming up with new movie ideas that will convince an audience to see their movie. Traditionally, executives secure life rights to produce biopics, obtain licensing agreements to adapt existing forms of media onto the big screen, and work with owners of promising intellectual property that can be adapted. However, Hollywood movies are struggling to recapture the box office successes as seen in the past. For one reason or another, movie goers have not been flocking to theaters to see the next big film. The goal of this project is to develop data-driven insights for new movie ideas.
In order to derive insights, we will be diving into data from the Internet Movie Database (IMDb). The dataset used in this project analysis comes from the IMDb non-commercial release data tables. We will explore key characteristics of successful movies in history, identify successful actors and filmmakers and examine downfalls in Hollywood history.
Analysis
Preparing, Cleaning & Loading the Dataset
The following packages will be used for this analysis: dplyr, tidyr, stringr, DT, ggplot2 and plotly. If these packages have not been installed in the system, they can be with the following code:
The dataset used in the analysis contains large files. It will take some time for the data to be downloaded and extracted. The following code will download the files and create six relevant dataframes that will be referenced throughout the analysis.
Note that the data we have extracted so far is large enough that we want to further downsize so we have a dataset we can analyze smoothly moving forward. The first thing we will do is modify the NAME_BASICS table to focus on people with at least two “known for” credits. The following code will help downsize the data present in NAME_BASICS.
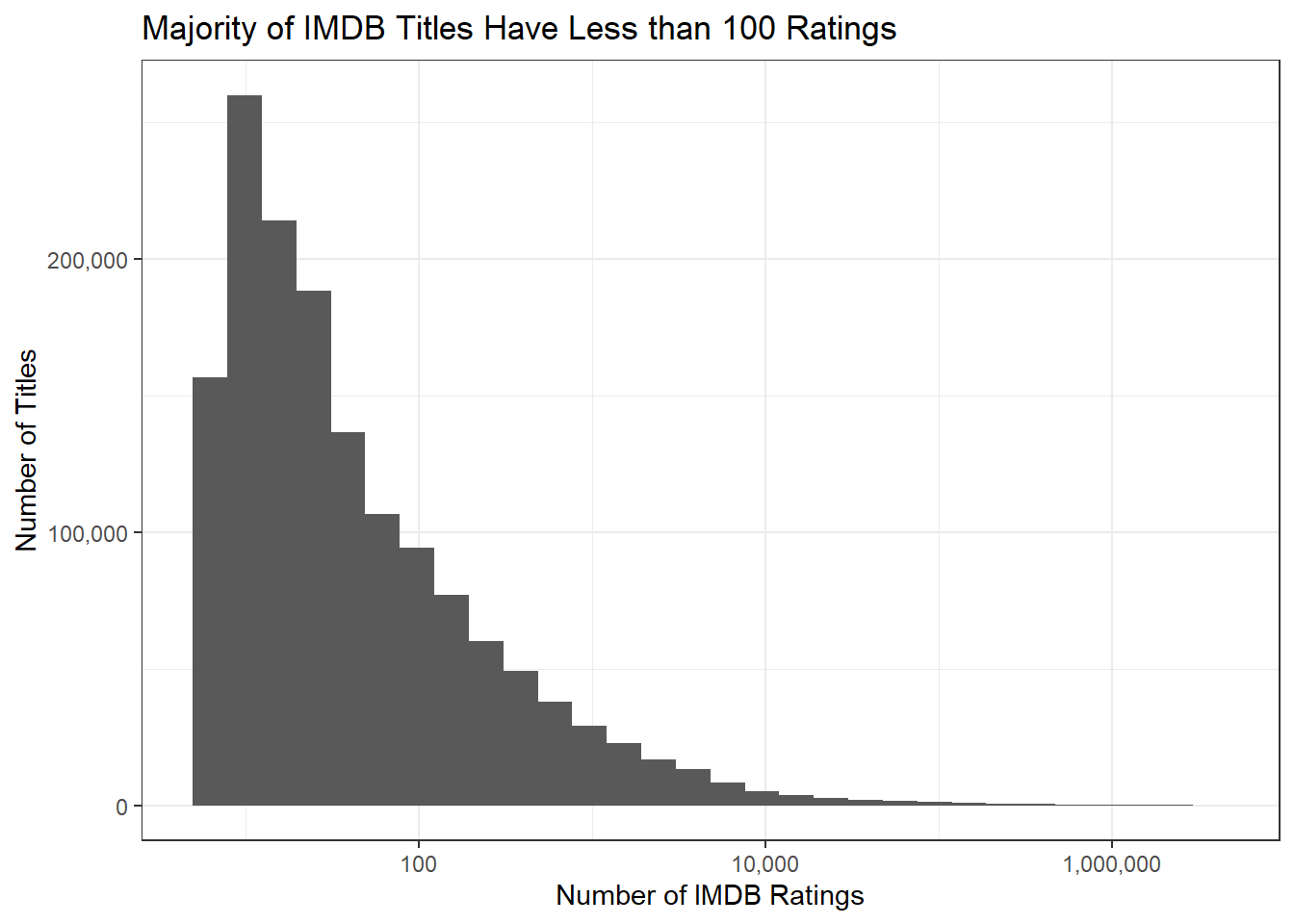
IMDb includes data for all sorts of media from major studios to independent producers. This includes obscure media that won’t be relevant to us for our analysis. The following code will visualize the distribution of ratings among the titles found on IMDb.
Code
TITLE_RATINGS |>ggplot(aes(x = numVotes)) +geom_histogram(bins =30) +xlab("Number of IMDB Ratings") +ylab("Number of Titles") +ggtitle("Majority of IMDB Titles Have Less than 100 Ratings") +theme_bw() +scale_x_log10(label = scales::comma) +scale_y_continuous(label = scales::comma)
The majority of the titles found in IMDb have less than 100 ratings. We will go ahead and drop any title with less than 100 ratings so our computers are able to run the analysis fluidly. We can apply this drop with the following code:
Now that we have downsized the amount of titles we will be analyzing, we can apply the same filtering to our other tables. This can be done by joining the TITLE_RATINGS table with the other TITLE_ tables with a semi_join.
The dataset is now more manageable to work with. We can now begin the analysis portion of this project.
Exploring The Data
Tidying Data Types
Using the glimpse function, we can examine each table to see the type/mode for each column. At first glance, the majority of the columns appear to be a character (string) vector. Some of these columns should be numerical values instead, but due to missing values R converted the missing numerical data into characters instead. We will need to fix this issue by using the mutate function along with as.numeric() and as.logical() on the desired columns. The following code will update the desired columns to the correct format.
Code
# Clean the NAMES_BASICS table, replace missing string values to numeric NA valuesNAME_BASICS <- NAME_BASICS |>mutate(birthYear =as.numeric(birthYear),deathYear =as.numeric(deathYear) )# TITLE_BASICS has 4 column types to correct, isAdult, startYear, endYear and runtimeMinutesTITLE_BASICS <- TITLE_BASICS |>mutate(isAdult =as.logical(isAdult),startYear =as.numeric(startYear),endYear =as.numeric(endYear),runtimeMinutes =as.numeric(runtimeMinutes) )# TITLE_EPISODES has 2 column types to correct, seasonNumber and episodeNumberTITLE_EPISODES <- TITLE_EPISODES |>mutate(seasonNumber =as.numeric(seasonNumber),episodeNumber =as.numeric(episodeNumber) )# TITLE_RATINGS has no columns to correct# TITLE_CREW has the correct column types but I want to convert the \\N values to NA insteadTITLE_CREW <- TITLE_CREW |>mutate(directors =na_if(directors, "\\N"),writers =na_if(writers, "\\N") )# TITLE_PRINCIPALS has the correct column types but I want to convert the \\N values to NA insteadTITLE_PRINCIPALS <- TITLE_PRINCIPALS |>mutate(job =na_if(job, "\\N"),characters =na_if(characters, "\\N") )
Caution
There are a few columns that contain multiple pieces of data in one cell. For example in the NAME_BASICS table, the primaryProfession and knownForTitles columns combine multiple values into one cell. We can use the separate_longer_delim function to break these values into multiple rows. To keep the analysis simple, we will use this function later when answering specific questions instead of breaking up the data beforehand.
Uncovering Insights From the IMDb Data
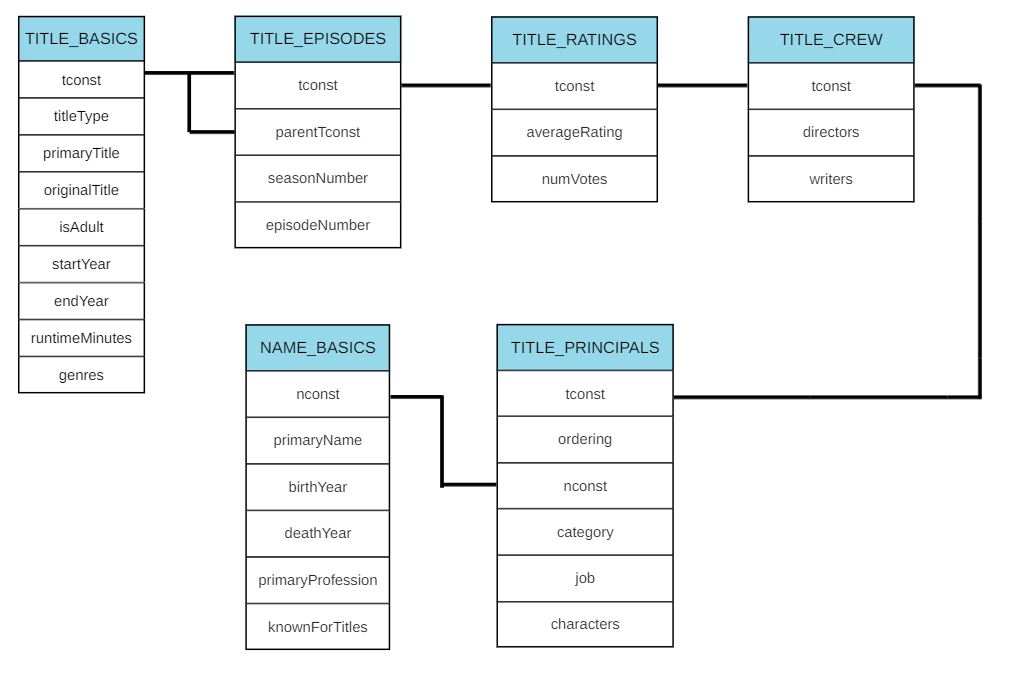
The first step in the analysis is to get a better understanding of the data we are working with. A series of questions are provided to get a grasp of what information we are able to derive from the provided data. To make things easier, creating a schema map of the tables helps us understand the relationships between each table. We will need to use multiple tables to derive insights to our questions.
Schema of Tables Used
The first set of metrics of interest are:
How many movies are in our data set? How many TV series? How many TV episodes?
Who is the oldest living person in our data set?
There is one TV Episode in this data set with a perfect 10/10 rating and 200,000 IMDb ratings. What is it? What series does it belong to?
What four projects is the actor Mark Hamill most known for?
What TV series, with more than 12 episodes, has the highest average rating?
The TV series Happy Days (1974-1984) gives us the common idiom “jump the shark”. The phrase comes from a controversial fifth season episode (aired in 1977) in which a lead character literally jumped over a shark on water skis. Idiomatically, it is used to refer to the moment when a once-great show becomes ridiculous and rapidly looses quality.
Is it true that episodes from later seasons of Happy Days have lower average ratings than the early seasons?
The first thing I want to do is get a breakdown of data in titleType to understand how the media is categorized by IMDb. The simplest way to do so is by running the following code:
The output lets us know exactly what I want to filter for to answer this question. Now that I know what parameters to filter on, the following code will count the amount of media that falls into each category.
Code
count_types <- TITLE_BASICS |>filter(titleType %in%c("movie", "tvSeries", "tvEpisode")) |># for this question I will only use movie, tvSeries, and tvEpisodegroup_by(titleType) |>summarise(count =n())datatable(setNames(count_types, c("Type", "Total")),options =list(pageLength =10, autoWidth =TRUE),caption ="Table 1: Number of movies, TV series, and TV episodes")
There are some things to consider when working with the provided data. In the NAME_BASICS table we are provided the columns birthYear and deathYear. The issue at hand to consider is that the value of NA in the deathYear column can either indicate the person is either still alive or the record is incomplete. To tidy this up, as of October 2024 the oldest person alive in the world was born in 1908. I will use this as a benchmark for the birth year when filtering for this person. Another thing to keep in mind is that the data does not provide a month or date, so we cannot distinguish who is older for people that share the same birth year. The following is a list of the 10 oldest living people in the data, however we cannot distinguish any further from the available data.
Code
oldest_living_person <- NAME_BASICS |>filter(is.na(deathYear), # NA in deathYear indicates person is living birthYear >=1908 ) |># data is incomplete from deathYear, only considering people born after 1908 as there are incomplete entries (the oldest verified living person in the world as of Oct 2024 was born in 1908)arrange(birthYear) |># order from oldest to youngestslice_head(n =10) |>select(primaryName)# note that only the birth year is available, no months or dates so this may not be as accurate as I'd likedatatable(setNames(oldest_living_person, c("Name")),options =list(pageLength =10, autoWidth =TRUE),caption ="Table 2: Oldest Living Person in IMDb")
IMDb has their rating system set up so that both a TV episode and TV series has its own separate ratings. For this metric, we want to focus strictly on the TV episode that has a perfect 10/10 rating with 200,000+ ratings. The first step is to identify that TV episode first. Once that has been identified, we can join that specific TV episode with the TITLE_EPISODES and TITLE_BASICS tables to get the series name. We find that the answer is none other than Breaking Bad - Ozymandias.
Code
# Find the episode with a perfect rating and over 200,000 ratingsperfect_episode <- TITLE_BASICS |>left_join( TITLE_RATINGS,join_by(tconst == tconst) ) |>filter( titleType =="tvEpisode", averageRating ==10, numVotes >=200000 )# Join back to TITLE_EPISODES and TITLE_BASICS to get the series nameperfect_episode_series <- perfect_episode |>left_join( TITLE_EPISODES,join_by(tconst == tconst) ) |>left_join( TITLE_BASICS,join_by(parentTconst == tconst) ) |>rename(episode_title = primaryTitle.x, # rename column to episode titleseries_title = primaryTitle.y ) |># rename column to series titleselect( series_title, episode_title )print(perfect_episode_series)
series_title episode_title
1 Breaking Bad Ozymandias
Within the NAME_BASICS table, each person has an associated list of titles they are known for found in the column knownTitles. This is a case where we want to use the separate_longer_delim function. We can get the titles easily by filtering specifically for Mark Hamill, but the results are stored as the identifier tconst. The last thing we need to do is join our results to the TITLE_BASICS table to get the actual name of the media Mark is known for.
Code
# Find the four projects Mark Hamill is known for firstmark_hamill <- NAME_BASICS |>filter(primaryName =="Mark Hamill") |>separate_longer_delim(knownForTitles, ",") |>select(knownForTitles)# this gives us the IDs, so we need to make further joins to get the names of the projects# Join results to TITLE_BASICS to get the name of the projectsmark_hamill_projects <- mark_hamill |>left_join( TITLE_BASICS,join_by(knownForTitles == tconst) ) |>select(primaryTitle)datatable(setNames(mark_hamill_projects, c("Project Title")),options =list(pageLength =10, autoWidth =TRUE),caption ="Table 3: The 4 Projects Mark Hamill Is Most Known For")
There are two trains of thoughts I have when approaching this question. A TV series and TV episode both have their own ratings. The first approach is to strictly focus on the average ratings on the TV series itself. The second approach is to find the average ratings among the episodes within a TV series. I will demonstrate how these two distinct approaches produce different answers. Before doing either analysis, I want to create a table that only includes series that have more than 12 episodes.
Code
tv_series_12 <- TITLE_BASICS |>filter(titleType =="tvSeries") |># Only want TV seriesleft_join( TITLE_EPISODES,join_by(tconst == parentTconst) ) |># Join with TITLE_EPISODES to count number of episodesgroup_by(tconst, primaryTitle) |># Group by series to count episodessummarise(total_episodes =n()) |># Count total number of episodesfilter(total_episodes >12)
Now that we have a list of TV series with more than 12 episodes, we can continue our analysis. The first analysis will look at the TV series ratings itself:
Code
highest_rated_tv_series <- tv_series_12 |>left_join( TITLE_RATINGS,join_by(tconst == tconst) ) |># Join with TITLE_RATINGS to get average ratingsungroup() |>arrange(desc(averageRating)) |>select(tconst, primaryTitle, averageRating) |>slice_head(n =10)datatable(setNames(highest_rated_tv_series, c("ID", "Title", "Average Rating")),options =list(pageLength =10, autoWidth =TRUE),caption ="Table 4: Highest Rated TV Series (Series Ratings)")
The second approach is averaging the episode ratings for the series:
Code
# find the series and average rating by aggregating the episode ratingsseries_ratings_byEpisode <- TITLE_EPISODES |>semi_join( tv_series_12,join_by(parentTconst == tconst) ) |>left_join( TITLE_RATINGS,join_by(tconst == tconst) ) |>group_by(parentTconst) |>summarise(avg_ratings =mean(averageRating)) |>arrange(desc(avg_ratings))# join onto the TITLE_BASICS table to get the name of the seriesseries_ratings_byEpisode <- series_ratings_byEpisode |>left_join( TITLE_BASICS,join_by(parentTconst == tconst) ) |>ungroup() |>select(parentTconst, primaryTitle, avg_ratings) |>slice_head(n =10)datatable(setNames(series_ratings_byEpisode, c("ID", "Title", "Average Rating")),options =list(pageLength =10, autoWidth =TRUE),caption ="Table 5: Highest Rated TV Series (Episode Ratings)") |>formatRound(columns ="Average Rating", digits =2)
We can see right away that the results from both approaches are very different from one another. Depending on the context, either answer is suitable. This all depends on how we define the average rating of a series. Some things to consider are for the second approach, it is possible for some episodes to have no ratings at all which can create some skewing of the mean rating. The TV series rating itself can also be different from the average ratings of the episodes.
Happy Days(1974 - 1984) has a total of 11 seasons. Since we can’t split it up evenly, I will define the early seasons as seasons 1-6 and the later seasons as season 7-11. To make sure I am looking at the correct series, the first thing to do is find the identifier for Happy Days(1974 - 1984).
Code
# Get tconst for the series first so we can find the episode ratings afterhappy_days_id <- TITLE_BASICS |>filter( primaryTitle =="Happy Days", titleType =="tvSeries", startYear ==1974, endYear ==1984 ) |>select(tconst)
Now that tconst has been identified, we can find the average ratings of the early and later seasons.
Code
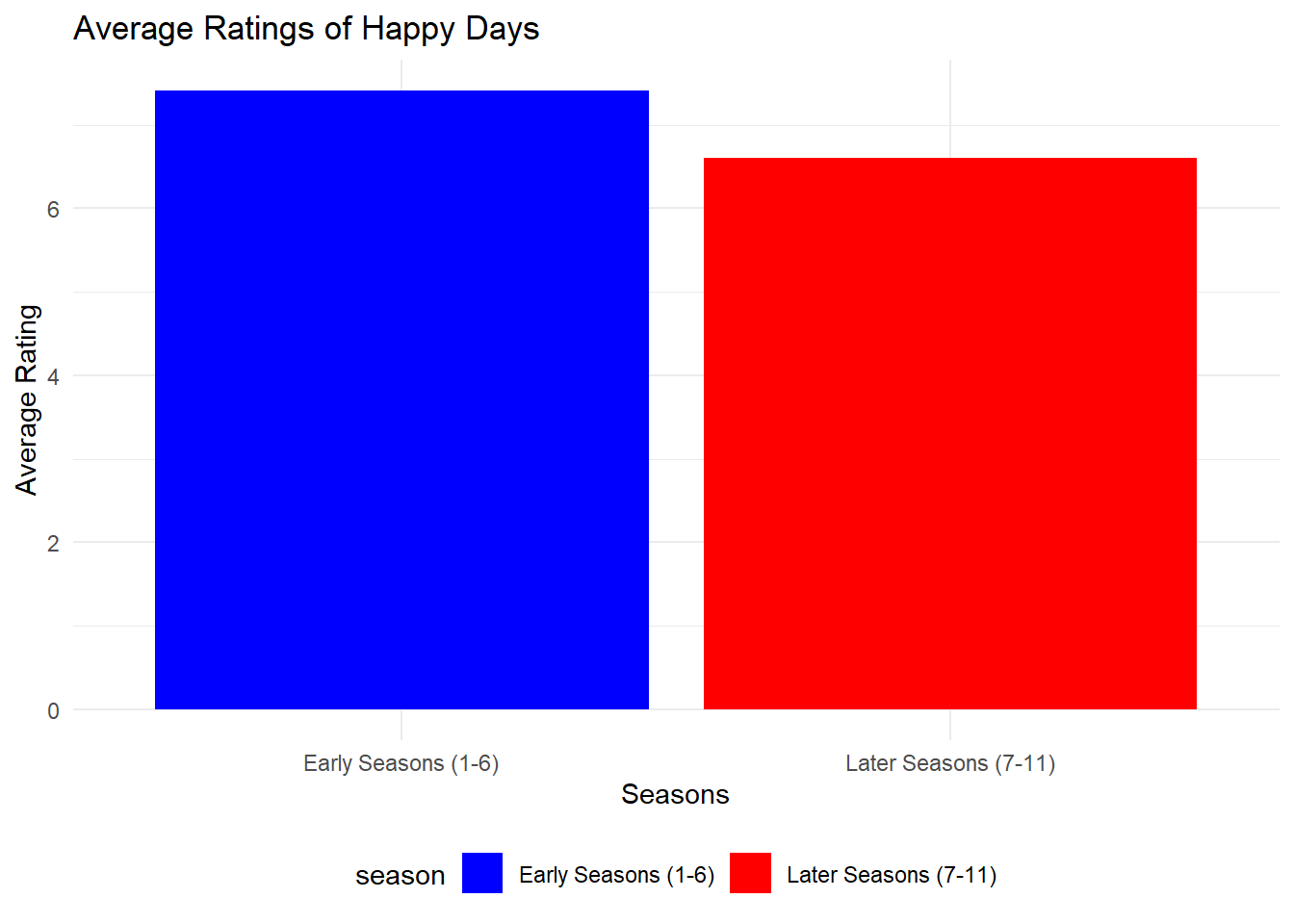
early_happy_days_episode_ratings <- TITLE_EPISODES |>semi_join( happy_days_id,join_by(parentTconst == tconst) ) |>left_join( TITLE_RATINGS,join_by(tconst == tconst) ) |>drop_na() |># get rid of any ratings that are NAfilter(seasonNumber <7) |># only care about seasons 1-6summarize(avg_rating =mean(averageRating)) |>mutate(season ="Early Seasons (1-6)")later_happy_days_episode_ratings <- TITLE_EPISODES |>semi_join( happy_days_id,join_by(parentTconst == tconst) ) |>left_join( TITLE_RATINGS,join_by(tconst == tconst) ) |>drop_na() |># get rid of any ratings that are NAfilter(seasonNumber >=7) |># only care about seasons 7-11summarize(avg_rating =mean(averageRating)) |>mutate(season ="Later Seasons (7-11)")combined_ratings <-bind_rows(early_happy_days_episode_ratings, later_happy_days_episode_ratings)ggplot(combined_ratings, aes(x = season, y = avg_rating, fill = season)) +geom_bar(stat ="identity", position ="dodge") +labs(title ="Average Ratings of Happy Days",x ="Seasons",y ="Average Rating" ) +theme_minimal() +scale_fill_manual(values =c("Early Seasons (1-6)"="blue", "Later Seasons (7-11)"="red")) +theme(legend.position ="bottom")
Based on the data provided, the later seasons did indeed have a lower average rating compared to the earlier seasons.
Quantifying Success
Recall that the goal of the analysis is to develop a new data driven model for coming up with new movie ideas. We want to quantify a movie’s success based on the data we have available to work with. Two metrics we can incorporate into a success factor is the IMDb ratings and number of voters. The IMDb ratings acts as an indicator of quality while the number of voters is an indicator of public popularity.
I will employ a success score for each movie based on IMDb ratings and number of voters. There are some things to consider beforehand, for example a movie can have a nearly perfect rating but have a small number of voters. We need to account for such cases when scoring the movies. To account for the effects of having a small number of voters, I will be employing a Bayesian average inspired model for my success scoring system. I will not delve into the mathematical theory behind this, but in general terms the Bayesian average will help account for title ratings with a lower number of voters. I encourage you to do your own research on the topic if it interests you.
Custom Success Metric
Based on the Bayesian average, I will define a new metric called weighted_rating for each movie title as a new rating measurement. The metric will be defined as:
As it stands, the variables avg_num_voters and avg_movie_rating are undefined in our data, but will be defined momentarily. The variable names are representative of what they define, we will be sampling the average number of voters and the average movie rating across all movies in our data. Having these metrics will give us a baseline to work with when quantifying the success of a movie.
The average movie rating is about 5.9 from our sample.
With our baselines variables established, I will now create a new table that consists of movie titles and their weighted rating. Note that this is not the final criteria used to define success. The weighted score is just a new rating number that accounts for the number of people that left a rating on the movie.
Code
movie_ratings <- TITLE_RATINGS |>left_join( TITLE_BASICS,join_by(tconst == tconst) ) |>filter(titleType =="movie") |>mutate(weighted_rating = ((averageRating * numVotes) / (numVotes +8700)) + ((8700*5.9) / (numVotes +8700))) |>select(tconst, primaryTitle, weighted_rating) |>arrange(desc(weighted_rating))limited_movie_ratings <- movie_ratings[1:1000, ] # limit to the first 1000 rows intending to save memory usagedatatable(setNames(limited_movie_ratings, c("ID", "Title", "Weighted Rating")),options =list(pageLength =10, autoWidth =TRUE),caption ="Table 6: Movie Titles With Weighted Rating") |>formatRound(columns ="Weighted Rating", digits =2)
The next step I will take is creating a new popularity factor to help define success. First, I am taking a look at the maximum & lowest number of voters a movie has.
Since there is such a large discrepancy between the maximum and minimum, a logarithmic scale should be used to scale the number of votes down to a reasonable factor.
Code
popularity_scaling <- TITLE_RATINGS |>left_join( TITLE_BASICS,join_by(tconst == tconst) ) |>filter(titleType =="movie") |>mutate(scaled_numVotes =log(numVotes +1)) |>select(tconst, primaryTitle, scaled_numVotes) |>arrange(desc(scaled_numVotes))limited_popularity_scaling <- popularity_scaling[1:1000, ] # limit to the first 1000 rows intending to save memory usagedatatable(setNames(limited_popularity_scaling, c("ID", "Title", "Scaled Number of Votes")),options =list(pageLength =10, autoWidth =TRUE),caption ="Table 7: Movie Titles With Scaled Votes") |>formatRound(columns ="Scaled Number of Votes", digits =2)
Tying it all together now, I will define a success score by multiplying the weighted rating and the scaled popularity factor. I’ve defined the new table as TITLE_RATINGS_MOVIES, and will use my new success_score metric for further analysis.
To check that the new success metric functions as anticpated, validation will be confirmed with the following:
Choose the top 5-10 movies on your metric and confirm that they were indeed box office successes.
Choose 3-5 movies with large numbers of IMDb votes that score poorly on your success metric and confirm that they are indeed of low quality.
Choose a prestige actor or director and confirm that they have many projects with high scores on your success metric.
Perform at least one other form of ‘spot check’ validation.
Come up with a numerical threshold for a project to be a ‘success’; that is, determine a value such that movies above are all “solid” or better.
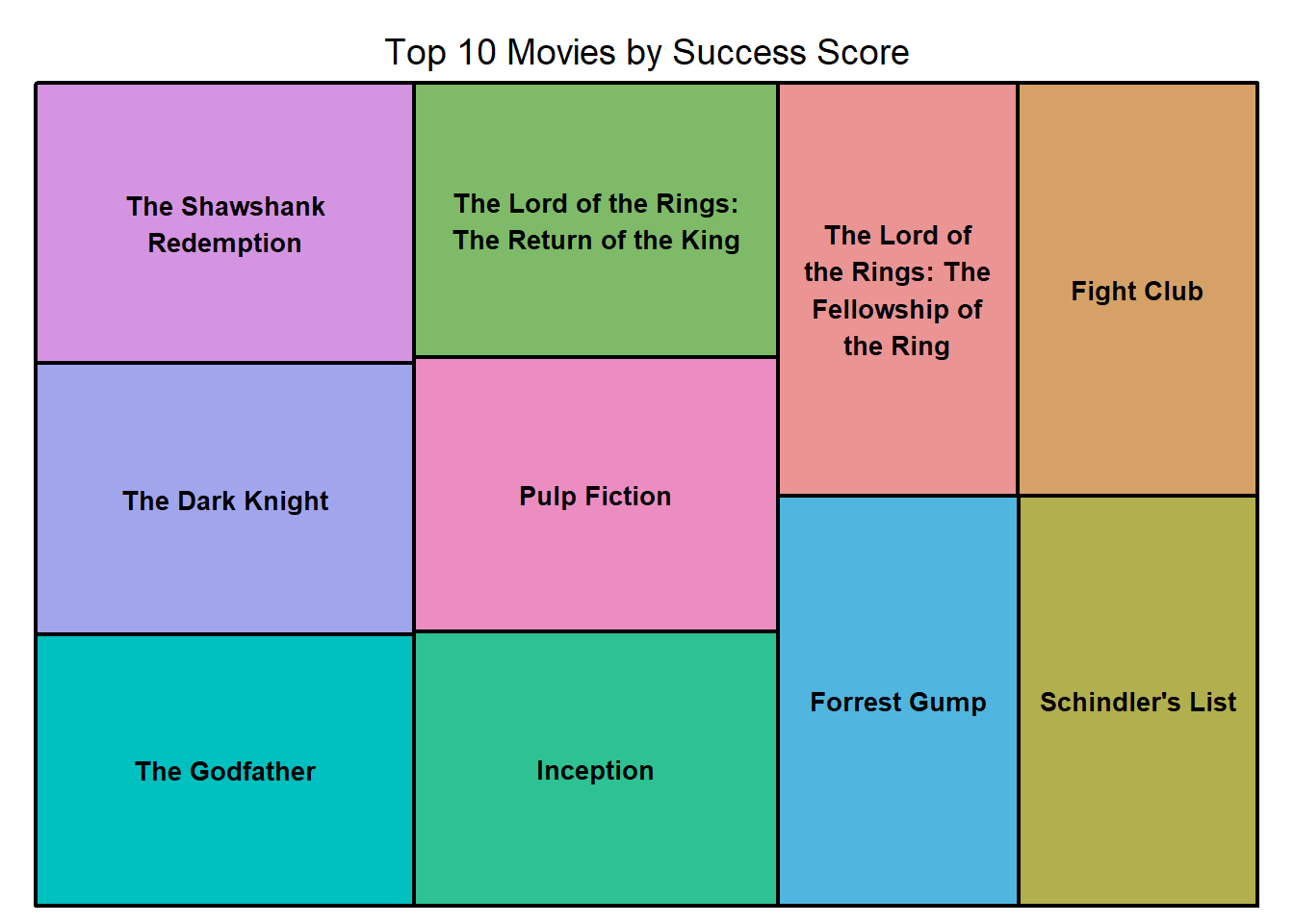
Taking a look at the top 10 movies using my success score, all the movies are box office successes with the exception of The Shawshank Redemption (however this would go onto be a financial success through other mediums). Box office financial information can be found here.
Taking a look at the generated list, we can pick out movies with lower success scores and a high number of voters. The 10 lowest scoring movies had at least 20,000 or more voters. Taking a look at the IMDb average rating to measure quality, none of these films were above a 2.0 rating.
For this validation method, I will be taking a look at Christopher Nolan’s work. Nolan’s works do score high under my defined success metric.
Code
NAME_BASICS |>filter(primaryName =="Christopher Nolan") # nm0634240, there are more than 1 Christopher Nolan in the database, so I'm making sure I'm choosing the correct one
nconst primaryName birthYear deathYear primaryProfession
1 nm0634240 Christopher Nolan 1970 NA writer,producer,director
2 nm3059799 Christopher Nolan NA NA \\N
3 nm9782801 Christopher Nolan NA NA camera_department
knownForTitles
1 tt6723592,tt0816692,tt1375666,tt0482571
2 tt1238854,tt0385423,tt0824052,tt1397480
3 tt16711020,tt10365464,tt5247284
I will check the success scores of the last 5 Oscar winners: Oppenheimer, Everything Everywhere All at Once, CODA, Nomadland & Parasite. All the oscar winners mentioned performed well under my success score.
To come up with a baseline for a “solid” movie, I want to take a look at the distribution of the scores in my rating system. I can use this by looking at the quantile distribution of the success_score. The 75% quantile shows us that 75% of the films fall under 43.6 points, setting this as a benchmark for success. Any movie with a success_score that is greater than or equal 43.6 is a “solid” movie.
Now that a “successful” movie is quantifiable, it is time to uncover trends found over time. Deriving insight from history can help determine what type of movies have been the most successful and point us in a direction when coming up with new movie ideas. The following questions can help determine what type of movie genre should be pursued for a Hollywood success.
Trends in Success Over Time
What was the genre with the most “successes” in each decade?
What genre consistently has the most “successes”? What genre used to reliably produced “successes” and has fallen out of favor?
What genre has produced the most “successes” since 2010? Does it have the highest success rate or does it only have a large number of successes because there are many productions in that genre?
What genre has become more popular in recent years?
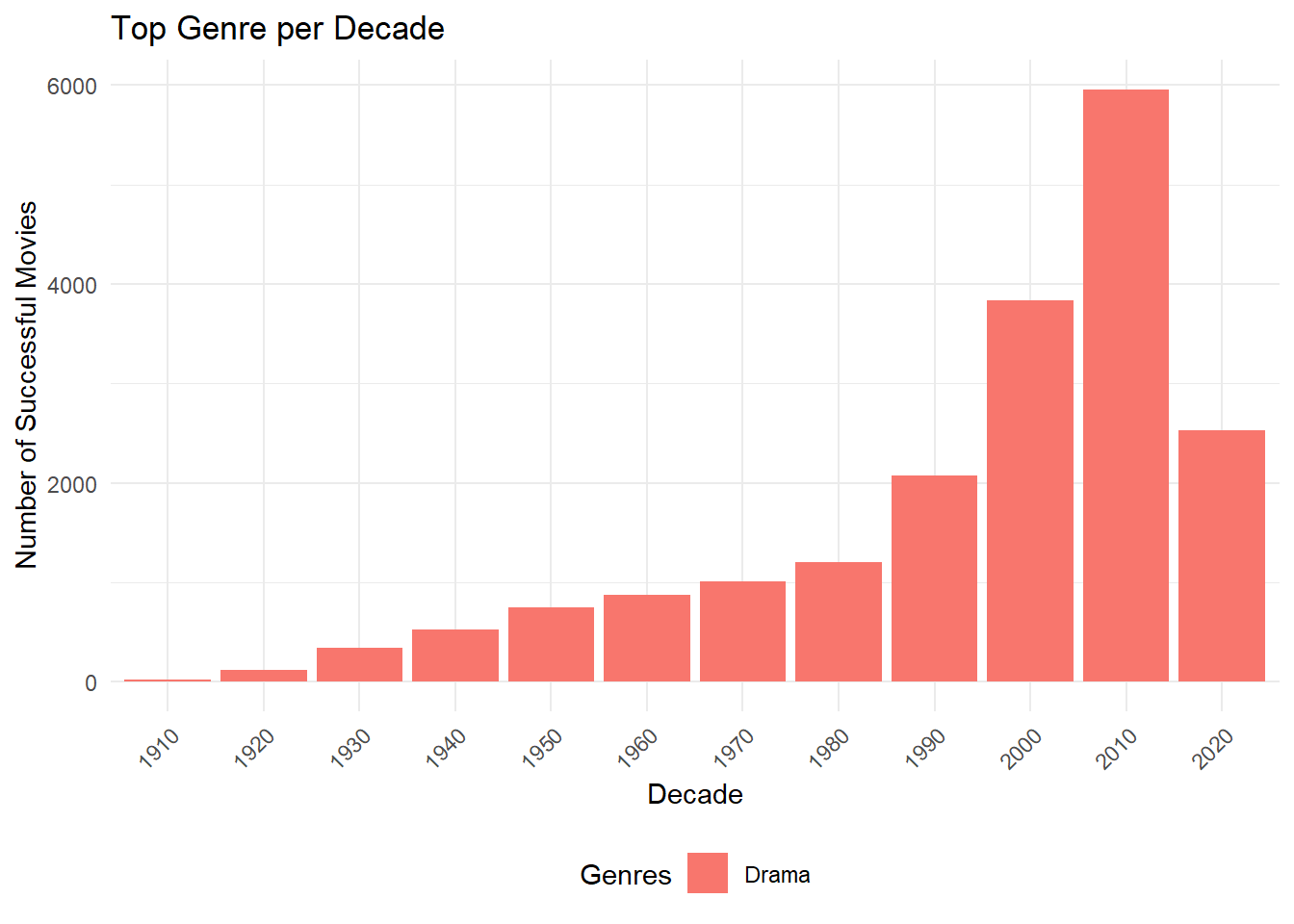
In order to identify the genre with the most “successes”, a new column will need to be created representing the decade the movie was released in. Once a decade has been assigned to each movie, we can further manipulate the data by grouping the genres together by decade to count the total number of movies in each section. Based on my own defined success score, the movie genre drama had the most successes in each decade represented by the data. Keeping this trend in mind, we will dive deeper into the success of dramas shortly.
Code
movie_genre_success <- TITLE_RATINGS_MOVIES |>left_join( TITLE_BASICS,join_by(tconst == tconst) ) |>filter(!is.na(genres) &!is.na(startYear.x)) |>separate_longer_delim(genres, ",") |>mutate(decade =floor(startYear.x /10) *10) |># create a decade columnselect(tconst, primaryTitle.x, success_score, startYear.x, decade, genres)decade_success <- movie_genre_success |>filter(success_score >=43.6) |>group_by(decade, genres) |>summarize(total_movies =n(), # Count the total number of successful movies.groups ="drop" ) |>group_by(decade) |>slice_max(total_movies, n =1) |>ungroup()ggplot(decade_success, aes(x =factor(decade), y = total_movies, fill = genres)) +geom_bar(stat ="identity", position ="dodge") +# Grouped barslabs(title ="Top Genre per Decade",x ="Decade",y ="Number of Successful Movies",fill ="Genres" ) +theme_minimal() +# Clean minimal themetheme(axis.text.x =element_text(angle =45, hjust =1),legend.position ="bottom" )
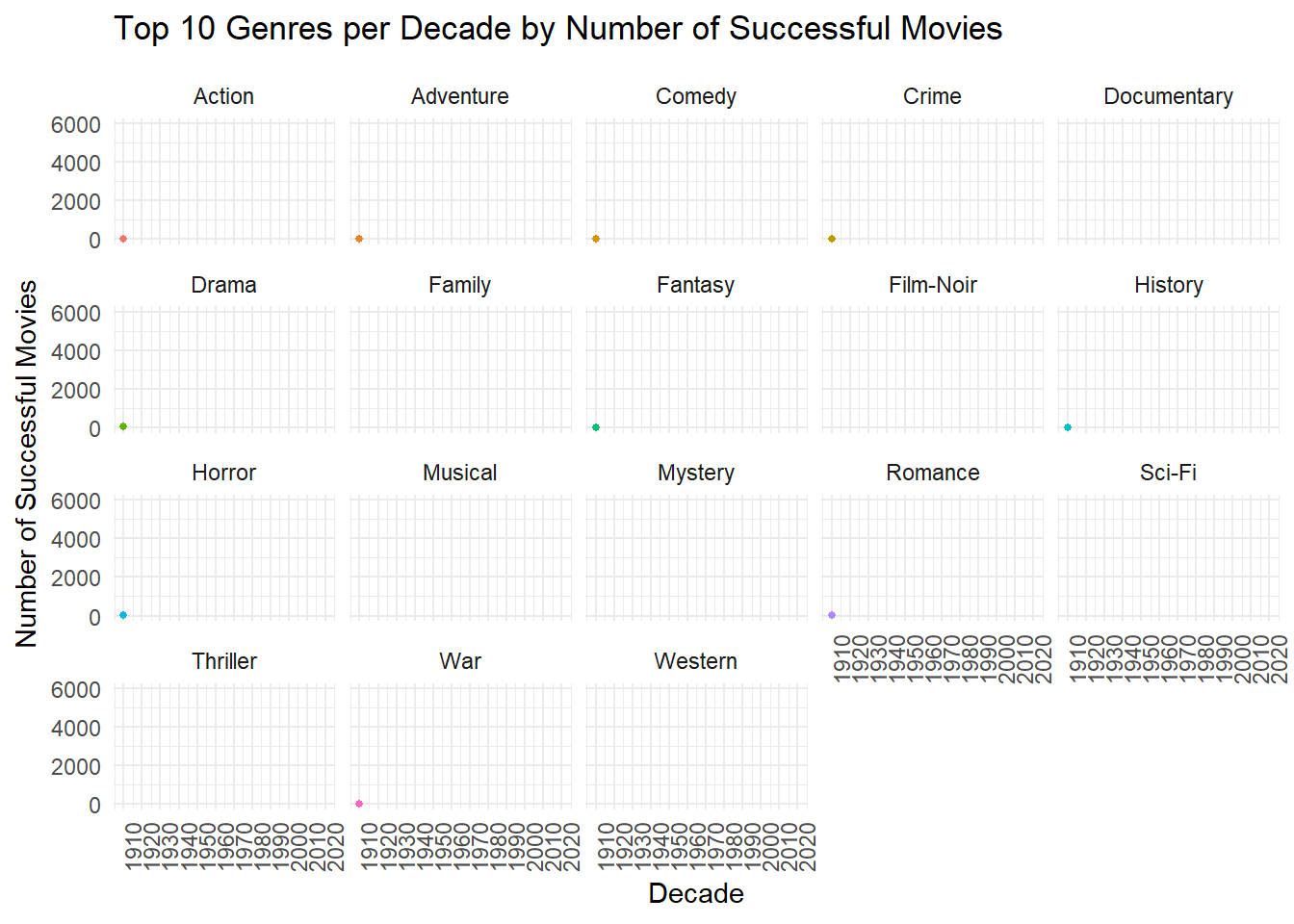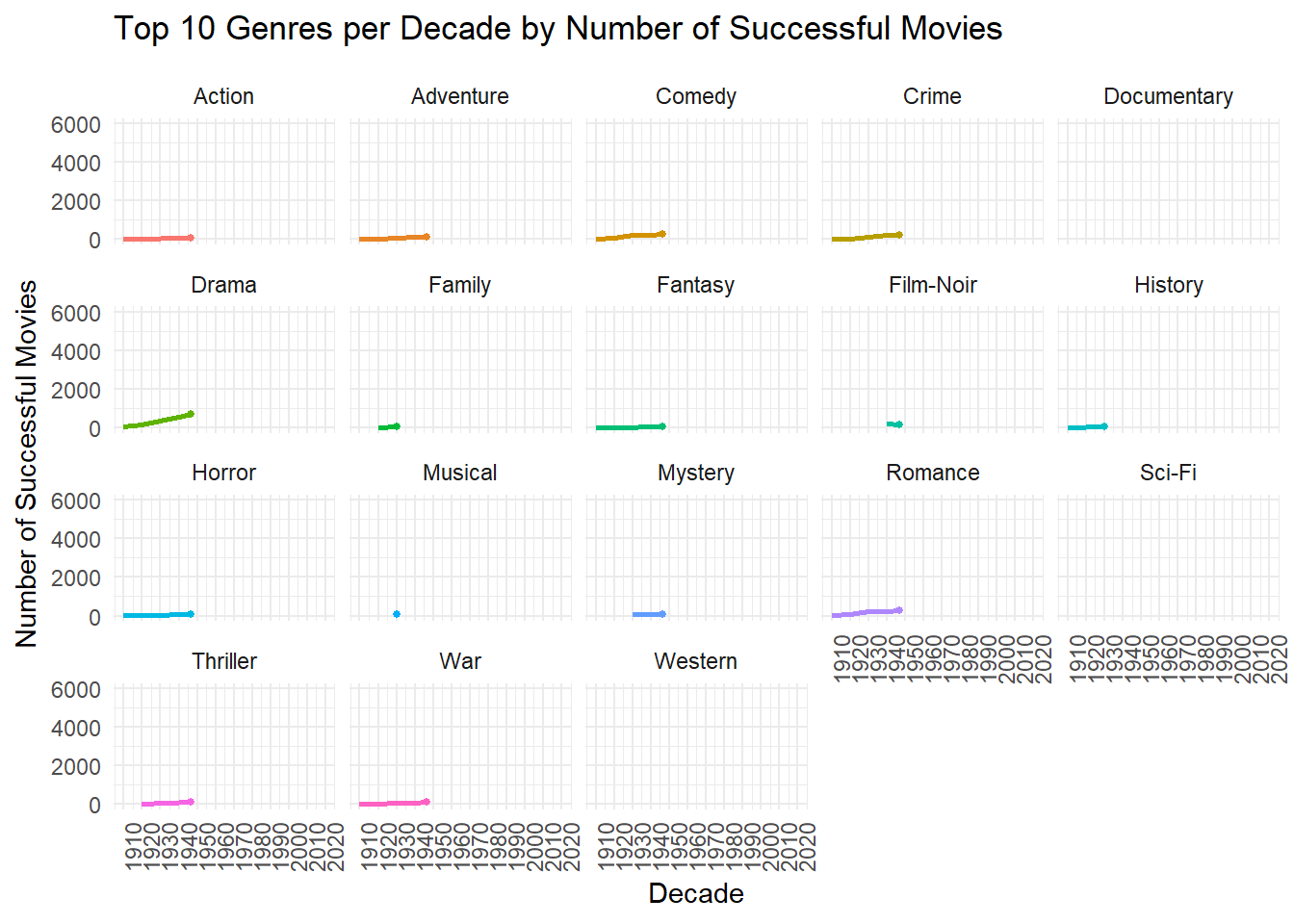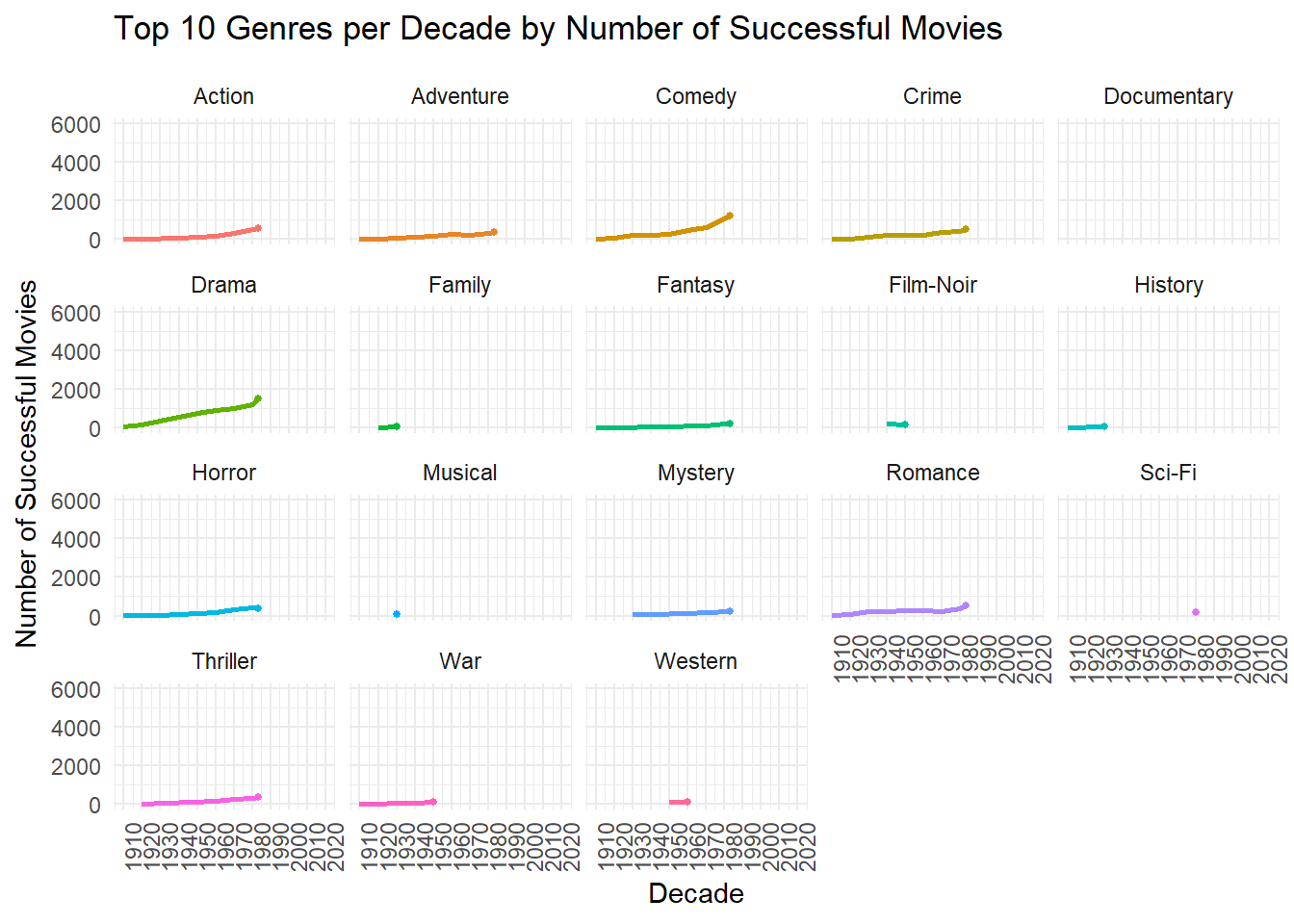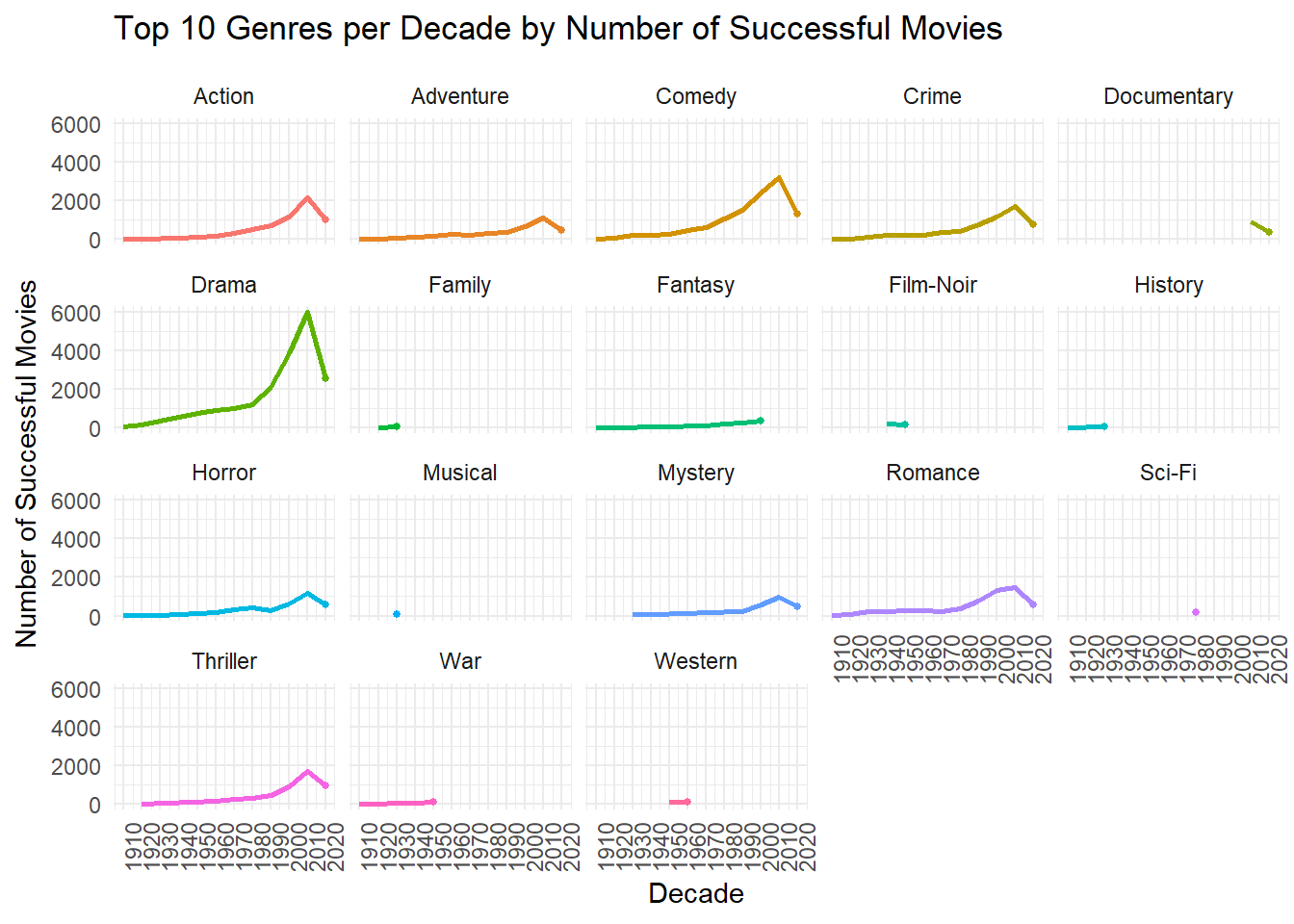
Once again, dramas dominate the genre field over time. Romance movies showed success in the past but have fallen out of favor in recent times. The following plot shows the top 10 genres by decade, the plot is interactive allowing users to manipulate the legend to hide any outputs. While the top genres are easily distinguishable, there are some overlapping data points that can be viewed better by hiding selective genre. Dramas have held onto the top spot throughout the time series, the 1980s was the only decade where comedies came close to taking the number 1 spot.
Code
# look at success of genre type by decade again, but this time including 10 genres to gauge how it changesdecade_success_top10 <- movie_genre_success |>filter(success_score >=43.6) |>group_by(decade, genres) |>summarize(total_movies =n(), # Count the total number of successful movies.groups ="drop" ) |>group_by(decade) |>slice_max(total_movies, n =10, with_ties =FALSE) |>mutate(rank =dense_rank(desc(total_movies))) |>ungroup() |>arrange(decade, rank) # Sort by decade and rank# visually plotinteractive_decade_success <-ggplot(decade_success_top10, aes(x = decade, y = total_movies, color = genres, group = genres)) +geom_line(linewidth =1) +# Plot the linesgeom_point(size =3) +# Add points at each decadelabs(title ="Top 10 Genres per Decade",x ="Decade",y ="Number of Successful Movies",color ="Genres", ) +scale_x_continuous(breaks =seq(min(decade_success_top10$decade), max(decade_success_top10$decade), by =10)) +# Set breaks every 10 yearstheme_minimal() +# Use a clean themetheme(axis.text.x =element_text(angle =45, hjust =1),legend.position ="bottom" )# Convert ggplot to interactive plot using plotlyggplotly(interactive_decade_success)
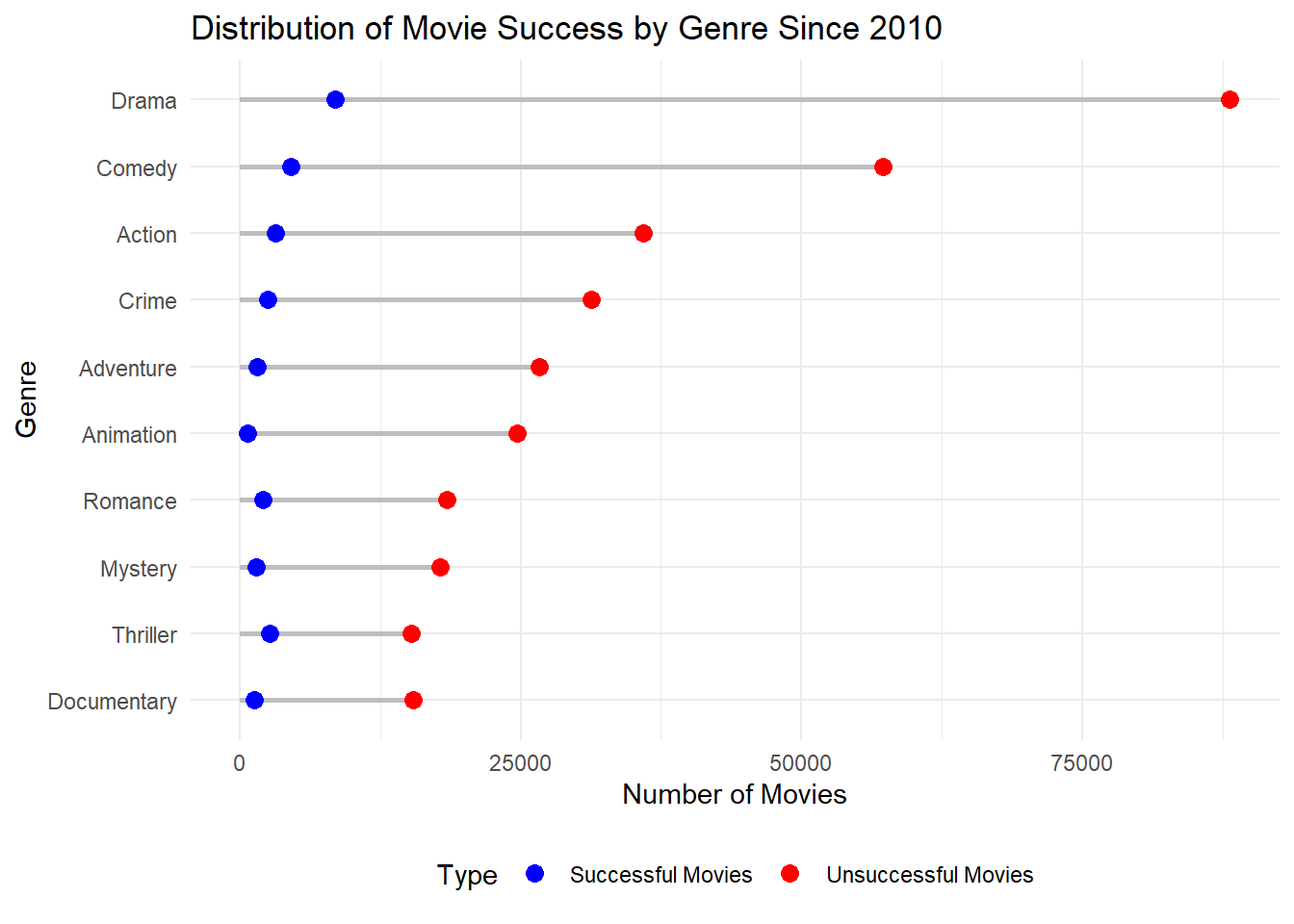
There is an ongoing trend here, the genre with most successes since 2010 is once again dramas. Taking a look at how many movies in each genre was produced since 2010 can help give context as well. There is definitely an impact by the sheer number of drama movies produced that help it have the highest success rate.
Code
# count number of successful projects since 2010 by genresuccesses_since_2010 <- movie_genre_success |>filter( success_score >=43.6, decade >=2010 ) |>group_by(genres) |>summarize(total_movies =n(), .groups ="drop") |>arrange(desc(total_movies))# count how many movies were made per genre since 2010movie_genres_produced <- movie_genre_success |>filter(decade >=2010) |>group_by(genres) |>summarize(total_movies_produced =n(), .groups ="drop") |>arrange(desc(total_movies_produced))# combine datagenre_distribution_2010 <-left_join(successes_since_2010, movie_genres_produced, by ="genres") |>mutate(`Unsuccessful Movies`= total_movies_produced - total_movies) |>arrange(desc(total_movies_produced)) |>slice_head(n =10)# pivot the data for long formatgenre_distribution_2010 <- genre_distribution_2010 |>pivot_longer(cols =c(`Unsuccessful Movies`, total_movies),names_to ="Type",values_to ="Count" ) |>mutate(Type =ifelse(Type =="total_movies", "Successful Movies", Type))# create a dumbbell plotggplot(genre_distribution_2010, aes(x = Count, y =reorder(genres, Count), group = Type)) +geom_segment(aes(xend =0, yend =reorder(genres, Count)), color ="grey", size =1) +# Draw lines to x = 0geom_point(aes(color = Type), size =3) +# Points for each typelabs(title ="Distribution of Movie Success by Genre Since 2010",x ="Number of Movies",y ="Genre" ) +scale_color_manual(values =c("Successful Movies"="blue", "Unsuccessful Movies"="red")) +theme_minimal() +theme(legend.position ="bottom" )
If we refer back to the Top 10 Genres per Decade plot, we see that the action genre separated itself from the other genres after the 2000s and has claimed to be the 3rd most popular genre since. Below we can see how the popularity changes over time for each genre to get a better individual understanding.
Code
animate_decade_genre <-ggplot(decade_success_top10, aes(x = decade, y = total_movies, color = genres, group = genres)) +geom_line(linewidth =1) +geom_point(size =1) +labs(title ="Top 10 Genres per Decade by Number of Successful Movies",x ="Decade",y ="Number of Successful Movies" ) +scale_x_continuous(breaks =seq(min(decade_success_top10$decade), max(decade_success_top10$decade), by =10)) +theme_minimal() +theme(axis.text.x =element_text(angle =90, hjust =1),legend.position ="none" ) +facet_wrap(~genres) +transition_reveal(decade) # animate the line growth over time (decade)animate(animate_decade_genre, renderer =gifski_renderer(file =paste0(save_directory, "/decade_success_animation.gif")))
Based on the insights we’ve uncovered, the genre I would like to pursue for my movie project is drama. According to IMDb, “the drama genre is a broad category that features stories portraying human experiences, emotions, conflicts, and relationships in a realistic and emotionally impactful way”. Taking a closer look at the most successful movies from my own metric in the table below, we see that dramas occupy 9/10 on the list. Due note that the majority of the titles have multiple genres. Drama coexists with other genres on this list, letting us know that success can be created by blending other genres together with drama. While I do want the main focus to be drama, I definitely will want to blend other elements in to give a more refined story.
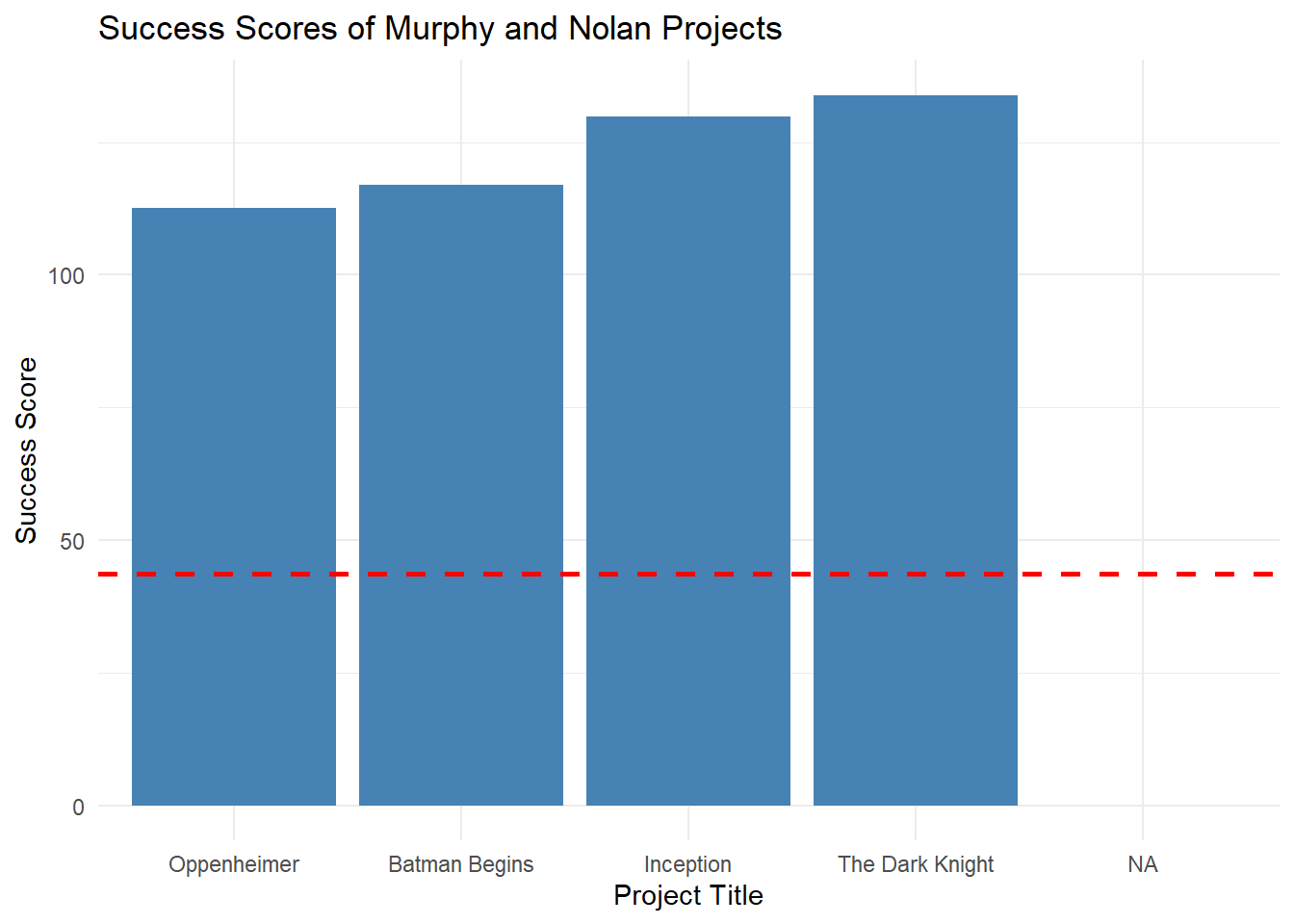
Selecting personnel is an important factor in producing a successful movie. For my movie, I would like to have Christopher Nolan as the director. The first actor I would like to pair is someone who has had success in the past with Nolan. I’ve chosen Cillian Murphy to join my project. The pair has demonstrated they work well together and have successful movies. The graph below shows the four projects they have worked on together. The dotted red line represents the solid success score as discussed earlier. The success scoring system has all of the titles exceeding the baseline, indicating that this director-actor duo is a good choice based on the provided data.
Code
murphy_nolan_projects <- TITLE_PRINCIPALS |>filter(nconst %in%c("nm0634240", "nm0614165")) |>distinct(tconst, nconst) |># ensure only distinct person-title pairsgroup_by(tconst) |>summarize(duo_works =n()) |># counts distinct personnelfilter(duo_works ==2) # only keep titles where both are presentmurphy_nolan_projects <- murphy_nolan_projects |>left_join( TITLE_RATINGS_MOVIES,join_by(tconst == tconst) ) |>select(tconst, primaryTitle.x, success_score, startYear)ggplot(murphy_nolan_projects, aes(x =reorder(primaryTitle.x, success_score), y = success_score)) +geom_bar(stat ="identity", fill ="steelblue") +# Bar chart with success scoresgeom_hline(yintercept =43.6, linetype ="dashed", color ="red", linewidth =1) +# horizontal line at y = 43.6 represents solid scorelabs(title ="Success Scores of Murphy and Nolan Projects",x ="Project Title",y ="Success Score" ) +theme_minimal()
The next actor I have in mind is an upcoming actor that could potentially become a Hollywood star in the future. I’ve chosen Paul Mescal to join the film, he has experience working in the drama genre and has recently started becoming more popular. At the time of this report, Mescal is set to star in Gladiator 2 which may end up being his big break cementing his name in Hollywood. The table below shows Mescal’s most known works. You can see that dramas are in all four titles, as well as some overlapping genres as well. Mescal’s familiarity with the genre will be an asset for success.
The movie I want to remake is Metropolis from 1927. The movie has an average IMDb rating of 8.3 with over 188,000 voters. The movie has drama and sci-fi listed as its genres. It is confirmed there has been no remake of the film since its initial release. I would have Cillian Murphy play Joh Fredersen and Paul Mescal play his son, Freder Fredersen.
Code
metropolis <- TITLE_BASICS |>filter(primaryTitle =="Metropolis", titleType =="movie")# if we print this original output, we will get two results for Metropolis. However upon further inspection, the Metropolis form 2001 has nothing in common with the movie I am looking to remake. We can move on by specifying the year.metropolis <- TITLE_BASICS |>filter( primaryTitle =="Metropolis", titleType =="movie", startYear ==1927 ) |>left_join( TITLE_RATINGS,join_by(tconst == tconst) ) |>select(primaryTitle, startYear, genres, averageRating, numVotes)datatable(setNames(metropolis, c("Project Title", "Release Year", "Genre(s)", "Average IMDb Rating", "Number of Votes")),caption ="Table 13: Metropolis")
Since the movie is from 1927, the likelihood of any of the key personnel involved in the original film being around is unlikely. We can still double check this using the data provided by IMDb. According to the Metropolis IMDb page the key people are Fritz Lang (director & writer), Thea von Harbou (writer), Brigitte Helm (star), Alfred Abel (star) and Gustav Fröhlich (star). The table below confirms that the key personnel are no longer alive.
Dramas have been the bestselling genre in the movie industry in the last century. Between the 1980s to the 2010s, the number of successful drama movies has increased by 394%. Part of the success comes from intertwining the drama genre with other genres to create a more profound story. Among the top ten successful movies, 90% are dramas. Taking a deeper look, 70% of the top ten successful movies blend drama with another genre type. Dramas captivate an audience using emotions and relatability. Tying in another genre adds another layer of complexity that enhances the viewing experience.
All of Christopher Nolan’s directorial works have been well received. 58% of the movies Nolan directed included drama as a genre. Cillian Murphy has been a frequent collaborator of Nolan. All their films together have been hits, their most recent work in Oppenheimer won an Oscar award. Recently, Paul Mescal has garnered attention for his work in the drama genre but has yet to reach stardom. Imagine bringing the three individuals together for a drama project. From Christopher Nolan, the visionary mind behind Inception; and from Cillian Murphy, beloved star of Oppenheimer; and from Paul Mescal, television icon of TV dramas, comes the timeless tail of Metropolis, a story of social inequality, dystopian society, and the effects of industrialization coming soon to a theater near you. Metropolis is primed for a remake, with the star power behind the project a box office hit is guaranteed.
Promotional Metropolis Remake Poster, generated by ChatGPT